Basic Computer Skills .htm
About us Contact
post comment Teb Computer Academy

TEB Computer Kids Academy

Data Science
Data Science - Data Preparation
Before you analyze data,
you must first of all extract the data,
and make it clean and valuable.
you can Extract and Read Data With Pandas -import/extract Data.
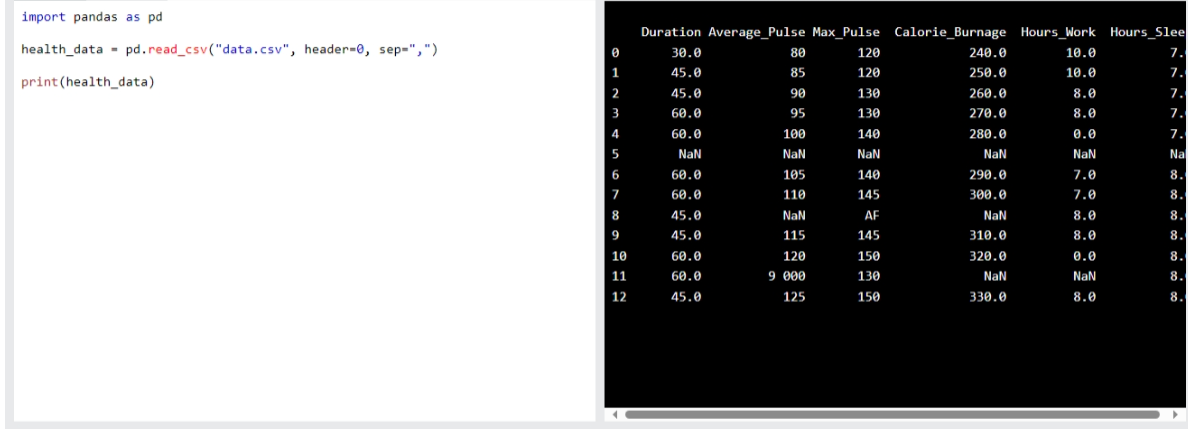
Here we use the read_csv() function to import a CSV file with this health data:
Now let us use pandas to import a health Data
Example
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data)
Output:
Example Explained
Import the Pandas library
Name the data frame as health_data
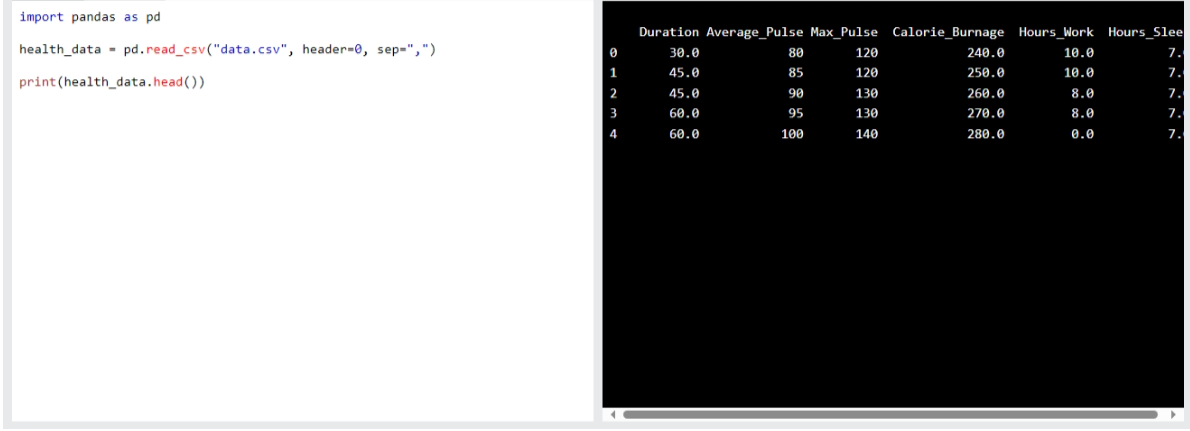
Note: you can use the head() function
to show the Top 5rows If you have a large CSV file:
Example
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data.head())
Output:
Data Cleaning
let us take a careful look at this data Report:
data set with NaN rows:
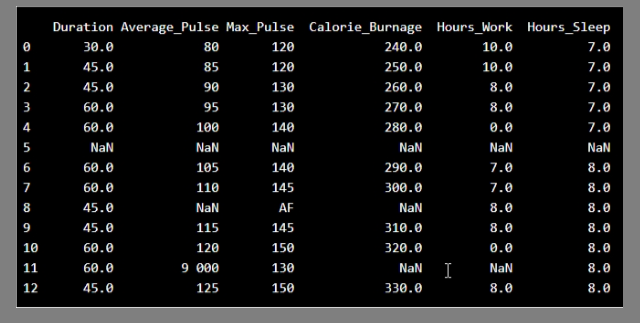
we must first of all clean the data in order to perform the analysis
this is because:
-There are some blank fields
-Average pulse of 9 000 is not possible
-9 000 will be treated as non-numeric, because of the space separator
-One observation of max pulse is denoted as "AF",
which does not make sense
The next thing is to clean the Data, how do we do that
Solution:
We can remove the rows with missing observations to fix this problem.
When we load a data set using Pandas,
all blank cells are automatically converted into "NaN" values
So, removing the NaN cells gives us a clean data set that can be analyzed.
We can use the dropna(): function to remove the NaNs
Example
health_data.dropna(axis=0,inplace=True)
print(health_data)
Output:
data set without NaN rows:
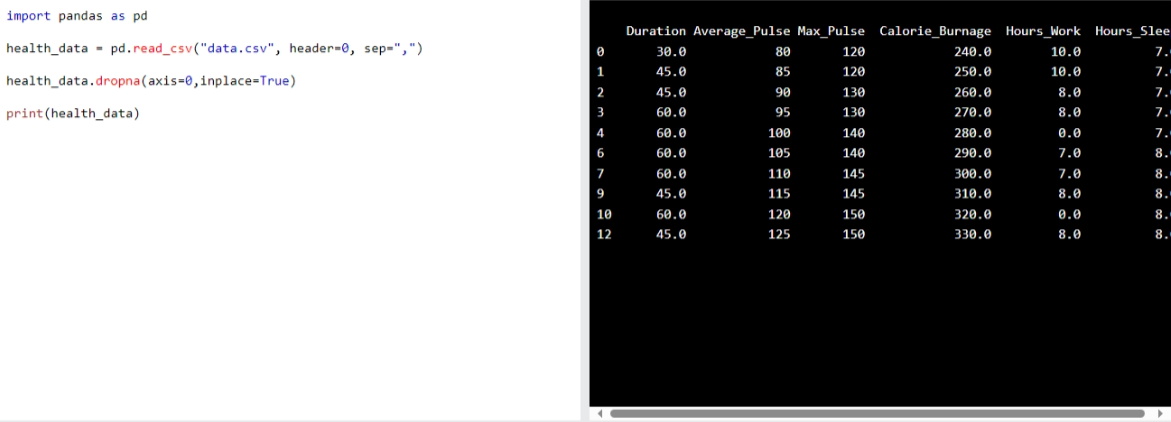
Please take a look at the Data above and this,
same data:
data set with NaN rows: and data set without NaN rows:.
With this short programm:
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
health_data.dropna(axis=0,inplace=True)
print(health_data)
we are able to drop the NANs
as well as other wrong informations
Now you can analyse the Data
Before you analyse Data,
you need to know the types of data you are dealing with.
Data Categories
You can split Data into two main categories:
1. Quantitative Data -
Can be expressed as a number or can be quantified.
Can be divided into two sub-categories:
- Discrete data:
Numbers are counted as "whole", e.g.
number of worshipers in a church, number of goals in a soccer game.
- Continuous data:
Numbers can be of infinite precision.
e.g. weight of a person, shoe size, temperature.
2.Qualitative Data -
Cannot be expressed as a number and cannot be quantified.
Can be divided into two sub-categories:
- Nominal data:
Example: gender, hair color, ethnicity
- Ordinal data:
Example: school grades (A, B, C, D),
economic status (low, middle, high, average)
Data Types
We can use the info() function to list the data types within our data set:
Example
print(health_data.info())
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data.info())
Output

this data set has two different types of data:
Float64
Object
Note: You cannot use objects to calculate and perform analysis.
You must convert the type object to float64
(float64 is a number with a decimal in Python).
You can use the astype() function to convert the data into float64.
This example converts "Average_Pulse" and "Max_Pulse"
into data type float64
(the other variables are already of data type float64):
Example
health_data["Average_Pulse"] = health_data['Average_Pulse'].astype(float)
health_data["Max_Pulse"] = health_data["Max_Pulse"].astype(float)
print (health_data.info())
Output
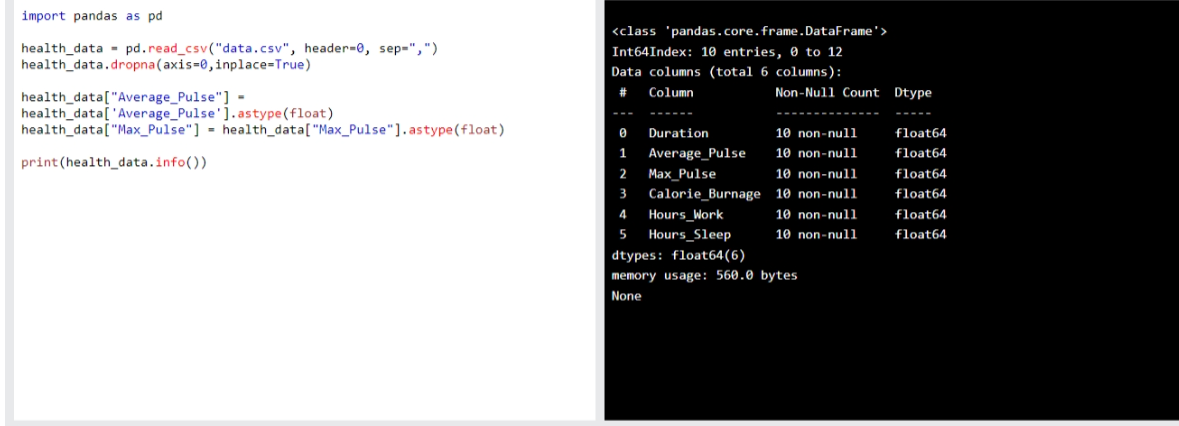
This data set has now, only float64 data types.
Analyzing the Data
After cleaning the data set, you can start now to analyze the data.
you can use the describe()function in Python to summarize data:
Example
use:
print(health_data.describe())
to output the Result.
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
pd.set_option('display.max_columns',None)
print(health_data.describe())
Output/Result:
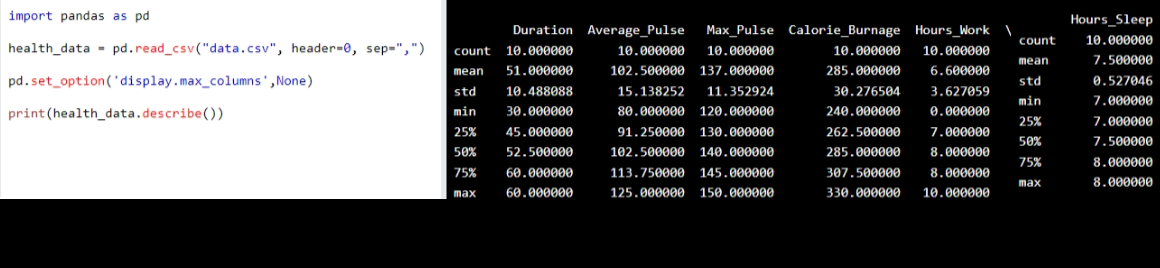
Output/Result:
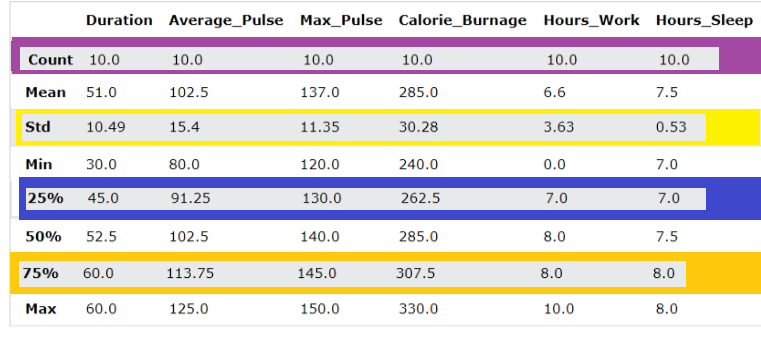
Example Explained
Count - Counts the number of observations
Mean - The average value
Std - Standard deviation (explained in the statistics chapter)
Min - The lowest value
25%, 50% and 75% are percentiles (explained in the statistics chapter)
Max - The highest value


Professional courses:
participant -Kids, Youths and Adults alike
learn and aquire these professional Courses
Professional Courses:






